Units of Work
Defining units of work and scopes of application cores is the single most important part of developing a system with Monstera. Everything else is just an implementation detail.
An application core is scoped to a single problem, a part of your larger domain. This problem should consist of many identical independent pieces. Each piece is a unit of work. The problem should be small enough so that its units can be handled by a single machine. And it should be large enough to benefit from having a significant part of your domain processed by a single program with all necessary data in proximity. An application core has only one dimension for growth: simply by the number of units of work. Your entire domain will be most likely split into multiple application cores. However, not all the logic will be implemented inside those cores, some stateless things are implemented outside.
This concept is similar to sharding/partitioning of databases (manual sharding, Vitess style, DynamoDB style, etc). A shard key is picked once in the begining and cannot be changed later. All related data is co-located on the same shard and can be wraped into a transaction or queried with secondary (sort) key.
The ideal situation for extracting units of work is when your domain is organized hierarchically. For example, Everblack Grackle, a service that provides distributed synchronization primitives (locks, semaphores, wait groups):
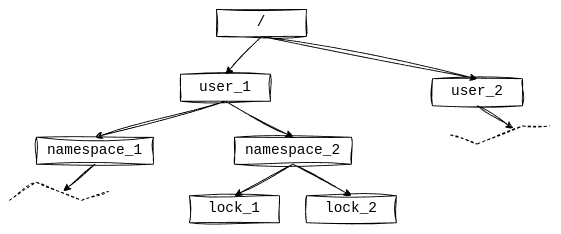
- The system has many users (multi-tenant)
- Each user has multiple namespaces (for organizational purposes)
- Each namespace has many locks (all locks in a namespace share common properties)
Multitenancy ensures that data of each user is isolated from other users. All operations of a user on its namespaces
are only concerned with namespaces of that user and nothing else. For example, there might be a limit on a total number
of namespaces per user. Or there might be a constraint that namespaces must have unique names. This is the scope of
NamespacesCore:
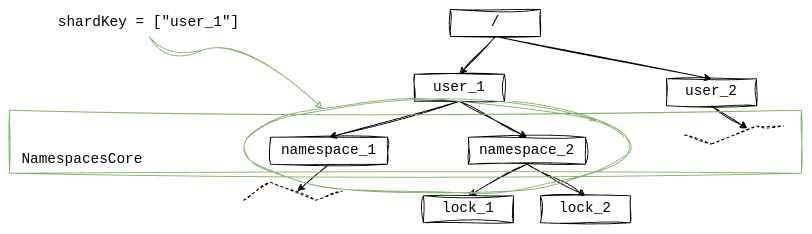
The path to a unit of work in that hierarchy is its shard key. All namespaces of the same user have the same shard key,
therefore, they belong to the same unit of work, therefore all requests for any of those namespaces will be processed
by the shard responsible for that key. There is a query ListNamespaces that returns all namespaces of a user. But
there are no queries that span multiple users. Although it is possible to implement such a query, this should not be
a primary use case for an application core.
Locks are organized into namespaces. There also might be constraints on name uniqueness or the total number of locks.
Locks in a namespace can share common properties, for example a default expiration time. Each lock has several related
objects: a write lock holder or a list of read lock holders. This is the scope for LocksCore:
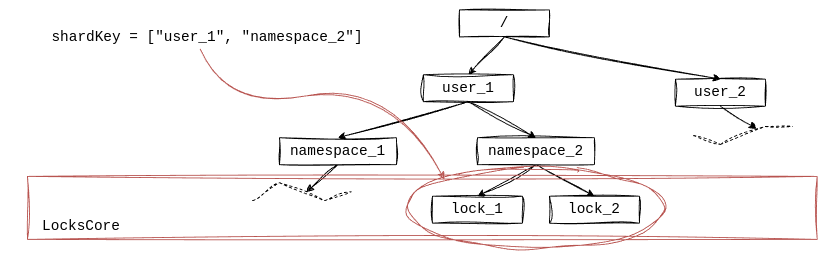
Similarly, there are also SemaphoresCore and WaitGroupsCore.
An application core scales by the number of units of work. Each unit should fit into a single machine (by CPU, RAM or disk space). A unit cannot be divided into smaller pieces later in the future. Therefore, it must be scoped carefully in the first place. Because an application core is mirroring a part of the domain, this domain can help estimating unit size. Having 50-100 namespaces per account should be more than enough for most use cases. Even 1000 namespaces is still around a megabyte of data. Each namespace can have 1M or even 10M active locks (there is nothing to store if it is not locked). Not every large system can perform 1M concurrent operations on a single type of objects. And 1M locks is roughly a gigabyte of data, which is small enough to fit on a single machine. The domain can also help estimating the throughput. “Hot partition” is a real problem here, but the domain can suggest how hot it can actually be.
On another side a unit of work should be big enough to benefit from having data in proximity. What does it mean? All update operations on a given unit are performed sequentially by a single process. This gives serializable transactions out of the box (and no race conditions). It makes sense to use this transactionality for a greater good:
- Uniqueness constraints
- Various limits
- Foreign key constraints
- Complex invariants
- Idempotency
- Conditional updates
- etc
Considerations
This approach might not work for you if:
- The data cannot be represented as a hierarchy at all or there are multiple different ways to build hierarchies from it.
- There is no domain aspect that can be used as a boundary for unit size or throughput.
- You are not sure that this will not change in the future.
- Transactions must cover several units (if money is moved from one account to another, then an account cannot be a unit of work).